从算力到服务,始终快人一步







推荐新闻
并行科技MaaS平台支持文心4.5系列开源模型调用
2025-07-02
6月30日,百度正式开源文心大模型4.5系列模型,并行科技MaaS平台第一时间完成接入。依托平台本身的海量算力基础与技术服务团队,致力于为开发者和科研工作者提供更便捷、更可靠、更低价的大模型服务。

文心4.5系列模型简介
文心4.5系列开源模型共10款,涵盖了激活参数规模分别为47B和3B的混合专家(MoE)模型(最大的模型总参数量为424B),以及0.3B的稠密参数模型。
针对 MoE 架构,文心4.5系列提出了一种创新性的多模态异构模型结构,通过跨模态参数共享机制实现模态间知识融合,同时为各单一模态保留专用参数空间。此架构非常适用于从大语言模型向多模态模型的持续预训练范式,在保持甚至提升文本任务性能的基础上,显著增强多模态理解能力。
文心4.5系列模型均使用飞桨深度学习框架进行高效训练、推理和部署。在大语言模型的预训练中,模型FLOPs利用率(MFU)达到47%。实验结果显示,该系列模型在多个文本和多模态基准测试中达到SOTA水平,在指令遵循、世界知识记忆、视觉理解和多模态推理任务上效果尤为突出。模型权重按照Apache 2.0协议开源,支持开展学术研究和产业应用。此外,基于飞桨提供开源的产业级开发套件,广泛兼容多种芯片,降低后训练和部署门槛。
文心4.5系列模型技术优势
1.多模态混合专家模型预训练
文心4.5 通过在文本和视觉两种模态上进行联合训练,更好地捕捉多模态信息中的细微差别,提升在文本生成、图像理解以及多模态推理等任务中的表现。为了让两种模态学习时互相提升,百度提出了一种多模态异构混合专家模型结构,结合了多维旋转位置编码,并且在损失函数计算时,增强了不同专家间的正交性,同时对不同模态间的词元进行平衡优化,达到多模态相互促进提升的目的。
2.高效训练推理框架
为了支持文心4.5 模型的高效训练,百度提出了异构混合并行和多层级负载均衡策略。通过节点内专家并行、显存友好的流水线调度、FP8混合精度训练和细粒度重计算等多项技术,显著提升了预训练吞吐。推理方面,百度提出了多专家并行协同量化方法和卷积编码量化算法,实现了效果接近无损的4-bit 量化和2-bit 量化。此外,百度还实现了动态角色转换的预填充、解码分离部署技术,可以更充分地利用资源,提升文心4.5 MoE 模型的推理性能。基于飞桨框架,文心4.5 在多种硬件平台均表现出优异的推理性能。
3.针对模态的后训练
为了满足实际场景的不同要求,百度对预训练模型进行了针对模态的精调。其中,大语言模型针对通用语言理解和生成进行了优化,多模态大模型侧重于视觉语言理解,支持思考和非思考模式。每个模型采用了SFT、DPO或UPO(Unified Preference Optimization,统一偏好优化技术)的多阶段后训练。
上并行科技MaaS平台 即刻调用文心4.5系列模型
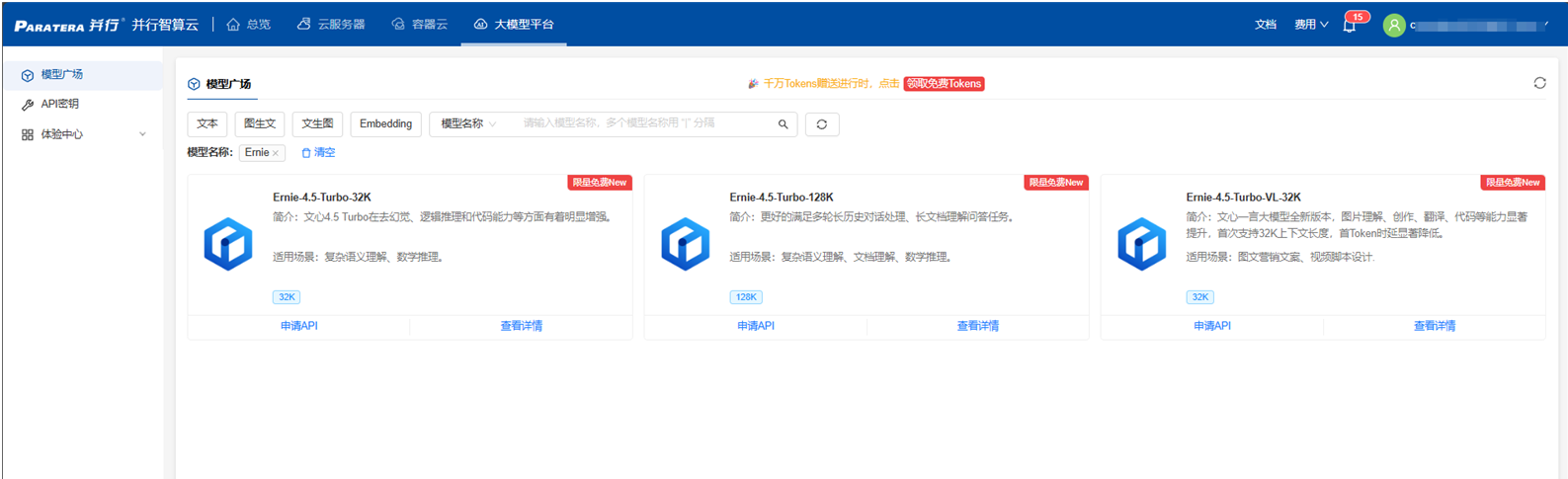
1、登录并行科技MaaS平台:
2、打开【模型广场】,选择文心模型,点击【申请API】即可跳转至API密钥创建页面,密钥可支持本平台所有模型~
TIPS:新用户千万tokens免费体验活动进行中~
3、选择Chatbox、Cherry Studio、代码接入等多种使用方式,均可完成接入使用~
详细接入手册,可参考平台【大模型平台使用指南-API使用文档】
并行科技MaaS平台
并行科技MaaS平台,是由并行智算云推出的一站式大模型服务平台,整合了各大热门模型,覆盖文本对话/视觉理解/图片生成/向量化等多个系列,支持论文润色/复杂推理/AI扩写/专业问答/长篇写作/知识图谱/代码生成/图片生成等多种场景。
平台优势:
模型选择丰富:并行科技MaaS平台集成了热门DeepSeek、GLM、Qwen、豆包系列模型,其他模型持续接入中;
覆盖场景完备:支持论文润色/复杂推理/AI扩写/专业问答/长篇写作/知识图谱/代码生成/图片生成等多种场景;
使用方式灵活:支持按需调用、本地私有化部署;
性价比优选:基于并行科技本身的海量算力基础,提供充足的高性能GPU资源,省去前期算力基础建设;
需求响应及时:专业技术服务团队,7×24小时响应,为应用落地保驾护航。
欢迎免费体验Paratera并行产品
国内领先的超算云和智算云算力服务商,主要业务包括通用云、行业云、AI云、设计仿真云
立即体验

股票代码
920493
电话:
资源全覆盖
体验极速
用户满意
省心计算
算力服务 就选并行
海量计算资源
减少排队
按需付费
7x24小时服务
—— 填写试用申请,并注册平台账户,专属客户经理将为您申请2000核时或200元卡时免费试算资源 ——







