
面向高校、科研院所、企事业单位在人工智能和高性能计算等方向的GPU算力需求,提供专业的GPU算力云。
并行智算云通过云主机和集群两大形态供给资源,满足人工智能场景和高性能计算场景中对灵活性和规模化等多样化需求;包括A100-80\A100-40\3090\V100-32\V100-16\A30\A10\T4\国产DCU等多种主流型号的海量资源;预置TensorFlow和PyTorch等框架,开箱即用;更有专家团队7×24小时在线的贴心服务,使科研工作者不为GPU算力分心,省心、高效专注科研。
深度神经网络、特征抽取、图像分类、目标检测、语义分割、表示学习、生成对抗网络、语义网络、协同过滤和机器翻译等研究成为近年热点,相关技术已应用于计算机视觉、自然语言处理、语音处理及推荐系统等领域。并行智算云主机可灵活地满足相关人工智能技术研究,在训练和推理阶段对GPU算力复杂多样需求。
单机提供NVIDIA Tesla最新架构8卡GPU,显卡直通,性能强劲,支持多机对卡并行提升算力。GPU卡型号丰富,满足训练和推理等多种场景需求。
灵活配置自主选择GPU卡数、CPU核数、存储容量、网络带宽及操作系统类型等,可根据业务需求灵活构建。
开箱即用预置TensorFlow、PyTorch、PyCharm、TensorBoard等框架环境,分钟级获得实例环境,即开即用。
灵活购买支持按量付费、包月包年等灵活的购买方式,起步“0”门槛。
常用环境TensorFlow、PyTorch、Caffe、MXNet、Keras、Anaconda、PyCharm、Jupyter、OpenCV、TensorBoard、Python、CUDA、TensorRT、NCCL等。
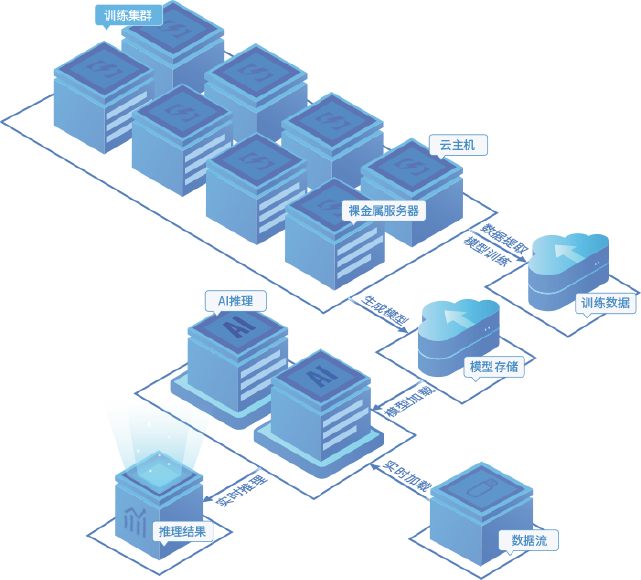
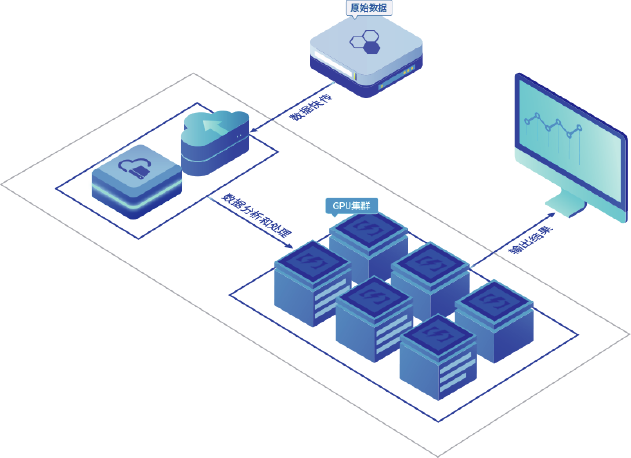
在大规模多核高性能计算场景中,GPU可大幅加速计算效率,使科研具有高出数量级的投入产出比,高性能程序GPU化趋势明显,GPU已广泛应用于生命科学、化学、材料、工业制造仿真设计、金融、气象海洋、油气能源等众多高性能计算领域。并行智算云GPU集群资源专为高性能计算场景而锻造。
提供NVIDIATesla最新架构GPU卡,以裸金属形态输出,消除虚拟化性能损耗,输出极致的性能。
高速互连100Gb/s高速互连,高性能并行存储,支持大规模并行。
弹性规模大规模集群架构及GPU队列资源池,可根据计算需求便捷获取数以百卡计算资源。
常用环境化学领域:AMBER、GROMACS、LAMMPS、NAMD等;
有限元分析:ABAQUS、Ansys、OpenFOAM、nanoFluidX等;
天气/环境建模:WRF、E3SM-EAM、COSMO等;
生命科学:Blast、AlphaFold2等。



•研发级业务移植服务支持 •IT维护方面无需分心
•起步投入门槛低,规避风险


 资源全覆盖
资源全覆盖 体验极速
体验极速 用户满意
用户满意 省心计算
省心计算sales@paratera.com
北京市海淀区西北旺东路10号院(东区)21号楼三盛大厦
Sansheng Plaza, Building 21, No. 10, Xibeiwang East Road, Haidian District, Beijing
010-82780567
并行科技公众号

—— 填写试用申请,并注册平台账户,专属客户经理将为您申请2000核时或200元卡时免费试算资源 ——




